Python 3.11.4 (tags/v3.11.4:d2340ef, Jun 7 2023, 05:45:37) [MSC v.1934 64 bit (AMD64)] on win32 Type "help", "copyright", "credits" or "license" for more information. >>> import requests >>> r = requests.get('https://quanben-xiaoshuo.com/n/wozaishourendaludangjisi/xiaoshuo.html') >>> r.text ''
defgetChapter(name, page): r = getHTML(f'{name}/{page}.html') r = r.xpath('//div[@id="articlebody"]/p/text()') # 此时的r是一个数组,每个元素是小说的一个段落 content = '\n'.join([' '+para for para in r]) # 遍历r中每一个元素,在行首加上空格,并用换行符分隔每一段落 return content
defgetChapterTitle(name, page): r = getHTML(f'{name}/{page}.html') return r.xpath('//h1[@class="title"]/text()')[0]
defgetChapter(name, page): r = getHTML(f'{name}/{page}.html') r = r.xpath('//div[@id="articlebody"]/p/text()') content = '\n'.join([' '+para for para in r]) title = getChapterTitle(name, page) return'\t' + title + '\n' + content
同理,可以获取书的书名,也可以获取这本书有多少个章节
1 2 3 4 5 6 7
defgetPageCount(name): r = getHTML(f'{name}/xiaoshuo.html') returnlen(r.xpath('//ul[@class="list"]/li'))
defgetBookTitle(name): r = getHTML(f'{name}/xiaoshuo.html') return r.xpath('//h1[@class="title"]/text()')[0]
最后一步:保存小说
有了上面写的那些函数,剩下的工作量就很小了
1 2 3 4 5 6 7
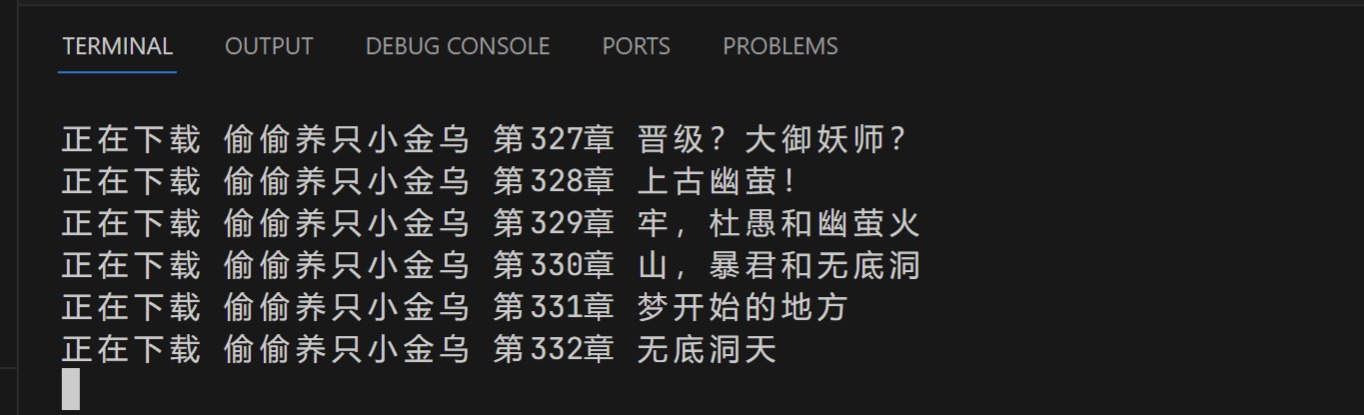
names = 'wozaishourendaludangjisi' page_count = getPageCount(name) title = getBookTitle(name) withopen(title + '.txt', 'w') as f: for i inrange(1, page_count+1): print(f'正在下载 {title}{getChapterTitle(name, i)}') f.write(getChapter(name, i) + '\n')
for name in names: page_count = getPageCount(name) title = getBookTitle(name) withopen(title + '.txt', 'w') as f: for i inrange(1, page_count+1): print(f'正在下载 {title}{getChapterTitle(name, i)}') f.write(getChapter(name, i) + '\n')


 微信
微信





{kind=link}