
CS231n/EECS598 学习笔记(三)
Lecture 8
AlexNet (2012)
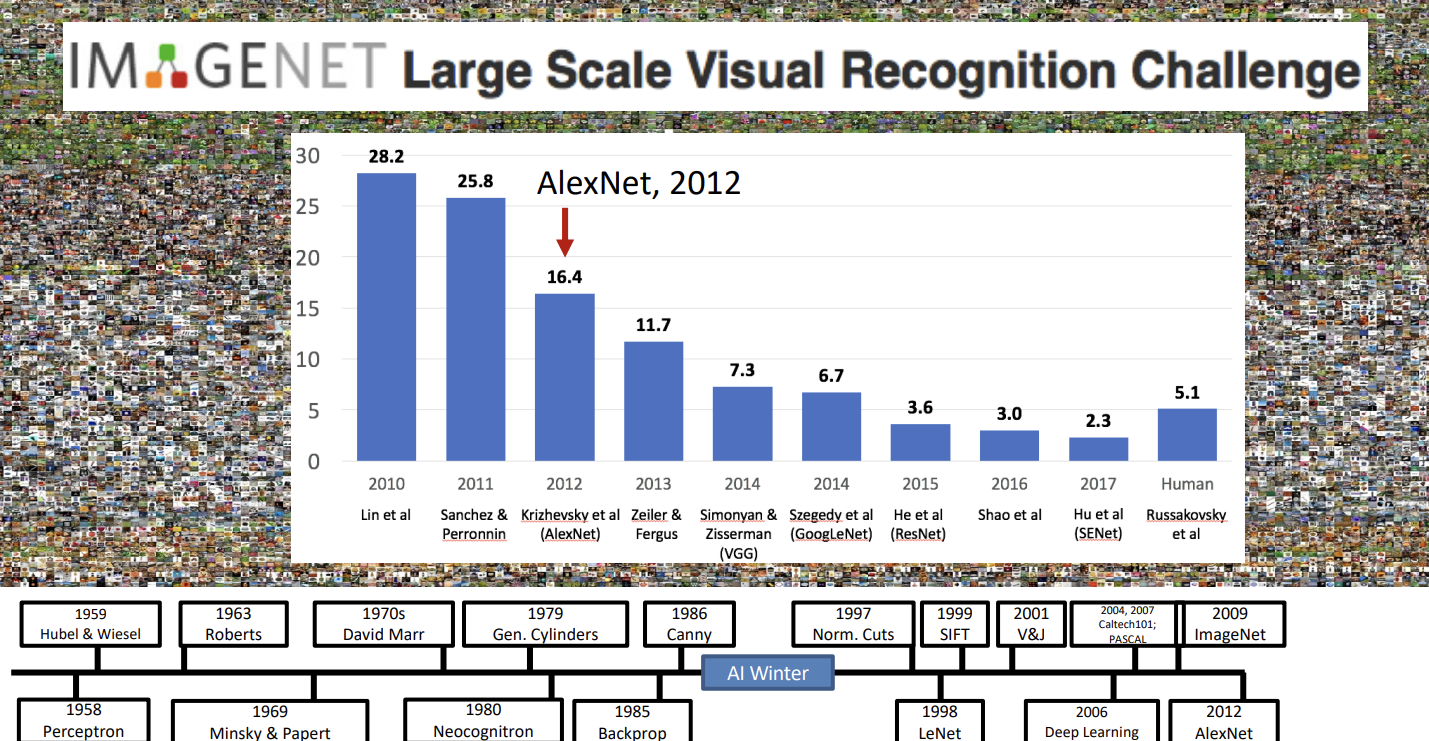
AlexNet是一个非常有影响力的卷积神经网络,Google Scholar显示,其原论文的引用已经达到了惊人的160203次。
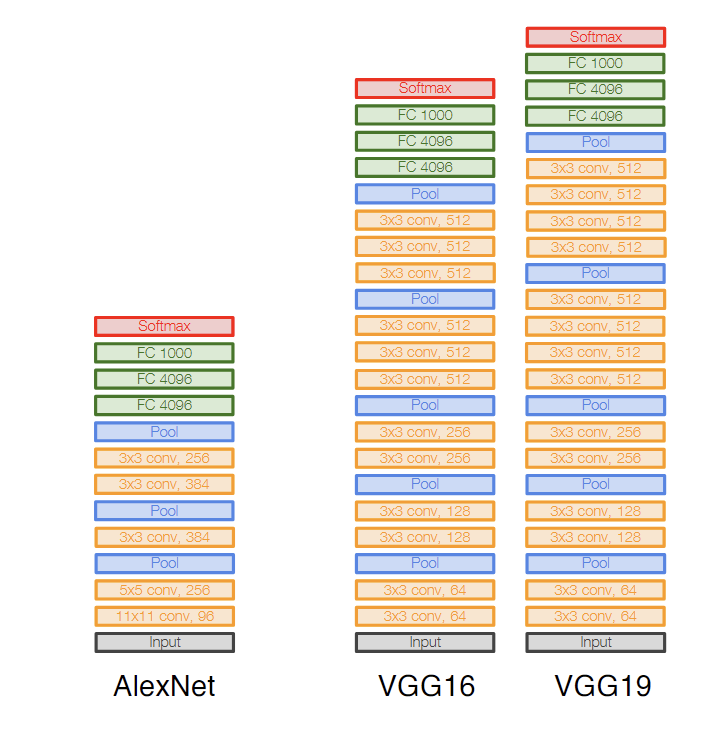
AlexNet的结构就是(conv + [pool]) * 5 + (fc + dropout) * 3,随着层数的增加,图片的长宽不断减少,而通道数不断增多。当通道数达到一定数量时,它们会flatten后作为特征输入全连接神经网络中。
分析内存使用和参数量,可以发现AlexNet有趣的特征,随层数增加,内存占用变少,而参数量增多,即所有内存基本都在前面的卷积层,所有参数量基本都在后面的全连接层。
ZFNet (2013)
ZFNet基本上就是一个更大的AlexNet,但是其基本结构依然是相同的,前面是卷积层和池化层,后面是全连接层。
VGG (2014)
AlexNet和ZFNet的网络结构参数,即卷积核形状, 每层通道数,池化层形状,都是通过尝试人工设置出来的。这让网络的scale up变得困难。VGG提出了一种系统的卷积神经网络设计方法:
- 所有卷积层都是3x3, 步长为1, 填充为1:两个3x3的卷积层优于一个5x5的卷积层,我们没有理由使用比3x3更大的卷积核。
- 所有池化层就是2x2, 步长为2,使得长宽减半,每经过一个池化层,卷积的通道翻倍。这样的设计使得FLOPs数在每层之间保持相同。
GoogleNet (2014)
GoogleNet很有趣,我们看到了ZFNet和VGG都开始叠参数量,神经网络变得越来越大。但是GoogleNet是一个关注效率的网络,因为谷歌想要在现实中使用这个模型。
GoogleNet为了达到这一点,卷积网络的空间维度下降得非常快,只经过了最初的几层,就从224x224降到了28x28。
GoogleNet还是用了一种叫做Inception的模块,Inception使用多种不同尺寸的卷积核并行,加速了计算效率。
GoogleNet还使用了一种叫做Global Average Pooling的技术,避免使用全连接层的巨大开销。
ResNet (2015)
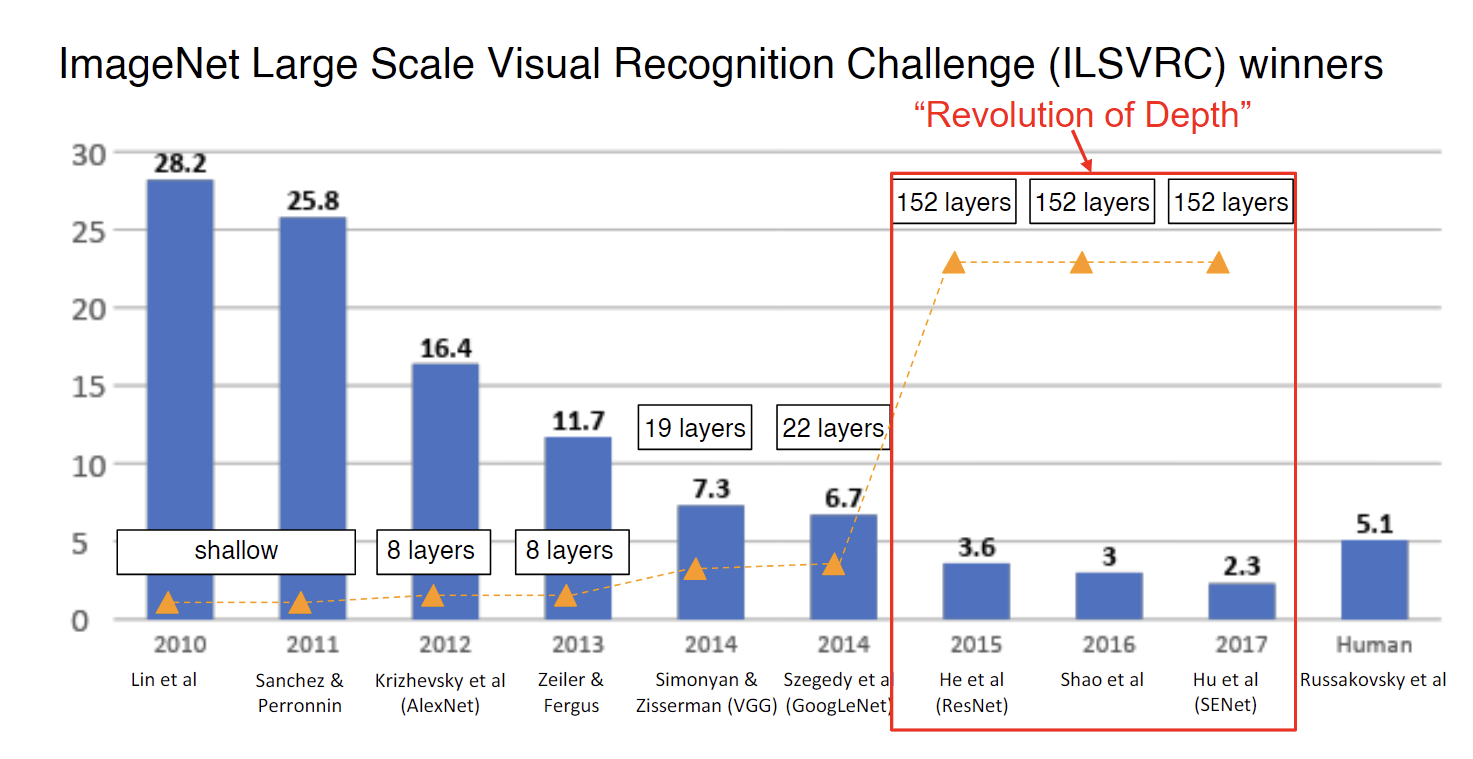
2015年之后,ImageNet获奖者的深度跳跃式地从十几层进化到几百层,发生了什么?
自从Batch Normalization出现以后,10+层的神经网络变得可行,然而再深度的神经网络却效果不好,反直觉的是五十多层的神经网络反而比二十多层的效果差,理论上来说深层的神经网络应该可以包括浅层的神经网络作为其中一部分,然后剩余的部分只要拟合单位矩阵就可以了。没有道理深层的神经网络更差。
一开始人们认为这是因为过拟合的问题,后来的一些研究表明,这些网络并非过拟合,而是不知怎么地欠拟合了。也就是说即使使用了batch normalization,现有的优化方式仍然失效。
上面提到了,如果有一个训练好的浅层神经网络,可以让深层神经网络的前几层和这个浅层神经网络一样,然后剩下的层什么都不做,只要拟合单位函数就可以了。然而实验证明我们连这样简单的策略都很难通过优化器得到。于是就有一个简单的思想,既然你需要单位函数,我就给你单位函数。原本是让某一层拟合,现在拟合,也就是说,如果需要单位函数,只要始终输出0就行了,这被称为残差链接。
残差链接可以促进深层神经网络的收敛,让深层神经网络的训练成为可能,这就是ResNet的基本思想。
就是这么一个非常简单的思想,促成了“Revolution of Depth”。从此之后,神经网络的层数大大增加。
未完成,待更新…
 微信
微信



{kind=link}