
SQL学习笔记(四)条件与分组语句
上一章节里我们使用了WHERE关键字进行了条件的筛选,实际上这样的关键字还有很多,以下是常用的一些。
GROUP BY
将数据按某个字段分组
1SELECT category, COUNT(*) FROM books GROUP BY category;
输出:
12345678┌─────────────────┬──────────┐│ category │ COUNT(*) │├─────────────────┼──────────┤│ Classic │ 6 ││ Fantasy │ 4 ││ Fiction │ 7 ││ Science Fiction │ 3 │└─────────────────┴──────────┘
ORDER BY
按某个字段排序,例如按每种分类的个数排序。
1SELECT category, COUNT(*) FROM books GROUP BY category ORDER BY COUNT(*);
输出:
12345678 ...

【CS50】课程推荐与学习心得
注:本文中所有标注*号的链接表示需要魔法上网
推荐
CS50真的是非常好的一门计算机入门课程,由哈佛大学David J. Malan教授主讲,它完全是面向对于计算机科学0基础的学习者,既简单易懂又干货满满,我真的难以相信,这是一门完全免费的课程。
看看CS50的目录,CS50是从scratch开始讲的,这足以证明它的初学者友好。
难能可贵的是,这门课并不因为简单就牺牲专业性。这并不是一门水课,它干货满满。从算法、数据结构到web三剑客html、css、js,再到web开发框架flask。全都是干货,况且每一次的CS50课程还配套相应的作业,有些作业难度不低。
这门课程很多内容都只是一个入门的引导,而不是一个完整的教程,但是正如David教授所说的那样,他不是要教你一种编程语言,他要教你 计算机科学 ,让你能够学会任何一门编程语言,让你有能力追逐最新的技术潮流。
学习心得
尽管我并不是零基础的学习者,但是听了这门课程我仍然收获颇丰,不仅收获了专业知识,也获得了很多乐趣,毕竟David教授是我见到的第一个能把课上得比看电影还有意思的教授。
非常羡慕Harvard这样的世界名校提供的资 ...
SQL学习笔记(三)基本查询语句
SQL中的函数
SQL中自带了很多函数,常用的有这几种:
函数
描述
AVG
求平均数
COUNT
计数
DISTINCT
去重
LOWER
小写
UPPER
大写
MAX
取最大值
MIN
取最小值
DISTINCT
假如我们想要查看所有的分类,可以这样子写:
1SELECT DISTINCT(category) FROM books;
输出:
12345678┌─────────────────┐│ category │├─────────────────┤│ Fiction ││ Science Fiction ││ Fantasy ││ Classic │└─────────────────┘
COUNT
查看有多少种分类:
1SELECT COUNT(DISTINCT(category)) FROM books;
输出是这样的
12345┌───────────────────────────┐│ COUNT(DISTINCT(category)) │├─────── ...
SQL学习笔记(二)创建一个表
在命令行里键入以下命令:
1sqlite3
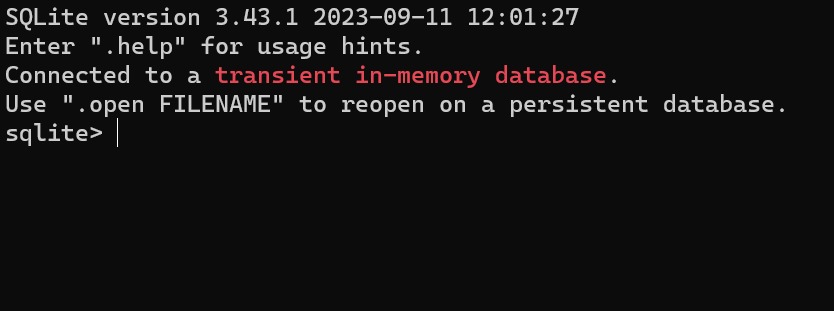
如果你按照上一个章节中那样配置好了环境,应该可以看到以下输出。
123# SQLite version 3.43.1 2023-09-11 12:01:27# Enter ".help" for usage hints.# sqlite>
看到输入提示符变成“sqlite>”,我们就进入了sqlite的命令行。
基本语句
数据库有四个基本操作CRUD,即Create增、Read查、Update改、Delete删,在SQL中分别对应以下语句。
增:CREATE, INSERT
查:SELECT
改:UPDATE
删:DELETE, DROP
创建一个表
使用以下命令来创建一个表,注意所有的SQL语句末尾都要有分号。
1CREATE TABLE 表名 ('列名' 数据类型, ...);
不同的数据库可能对相同的类型有不同的名称、不同的长度、数据范围
以sqlite为例,常用的数据类型有以下几种:
数据类型
描述
NULL
空值NULL
INTEGER
整数,具体位数取决于 ...
SQL学习笔记(一)安装SQLite
引入
现代的程序,无论是网站、手机app等等,往往都要处理大量的数据,这些数据需要通过**数据库(Database)**来管理。为了便于程序与数据库之间的交互,我们引入一门语言,SQL(Structured Query Language,结构化查询语言)。使用SQL可以方便地对 关系型数据库(Relational Database) 进行增、查、改、删等操作。
如果你不知道关系型数据库和非关系型数据库是什么,可以看看我的这篇文章
SQLite的安装
为了学习SQL,我们先来安装一个轻量级的关系型数据库 SQLite ,请与SQL区分,SQL是一种查询语言,SQLiete是一种数据库。
因为我们只是用来学习SQL语言,所以比起Oracle这样的庞然大物,使用轻量级的SQLite是更好的选择。当然,你学会了SQL之后,可以自由选择符合你需求的数据库,关系型数据库都使用统一的SQL语言,无需再次学习。
安装SQLite非常简单,访问SQLite官网的下载页面,下载你的系统对应的带有“Precompiled”前缀的压缩包。以windows x64系统为例,下载这两个文件,并把他们解压到相同的 ...
关系型数据库与非关系型数据库
关系型数据库(Relational Database)与非关系型数据库(NoSQL Database)有什么区别呢?请看下面的表格。
关系型数据库
非关系型数据库
数据结构
数据库表
不固定,如键值对(Key-Value)等
可扩展性
横向扩展较为困难,需要增加外部关联数据表
具有高度可扩展性
查询语言
SQL
通常具有自己的查询语言,没有SQL那样标准化
ACID
支持恢复、回滚、并发控制等
难以保证数据的完整性和安全性
ACID: 原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)
简单来说,关系型数据库就像Excel表格,非关系型数据库就像.json文件(当使用键值对数据结构时)。
关系型数据库更成熟稳定,非关系型数据库更灵活易扩展。
环境变量path是什么
有什么用
当你想要在命令行启动某个程序,通常你要cd进入到这个程序所在的目录,或者键入程序的完整路径。如果经常使用它,这样太繁琐了。环境变量path可以告诉命令行去哪里找程序的位置,这样,只需要键入程序名称,无需键入完整路径,就可以打开程序。
具体来说,搜索程序的顺序一般是这样的:
先在当前的工作路径寻找
如果未找到,在环境变量的path中寻找
如果仍未找到,报错
举个例子
假如我们用C语言写了一个简单的加法计算器
123456789101112// /root/myCommands/calculator.cpp#include<stdio.h>int main(int argc, char *argv[]) { int ans = 0, tmp, i; for (i = 1; i < argc; ++i) { sscanf(argv[i], "%d", &tmp); ans += tmp; } printf("%d\n", ans) ...
程序的内存布局
简介
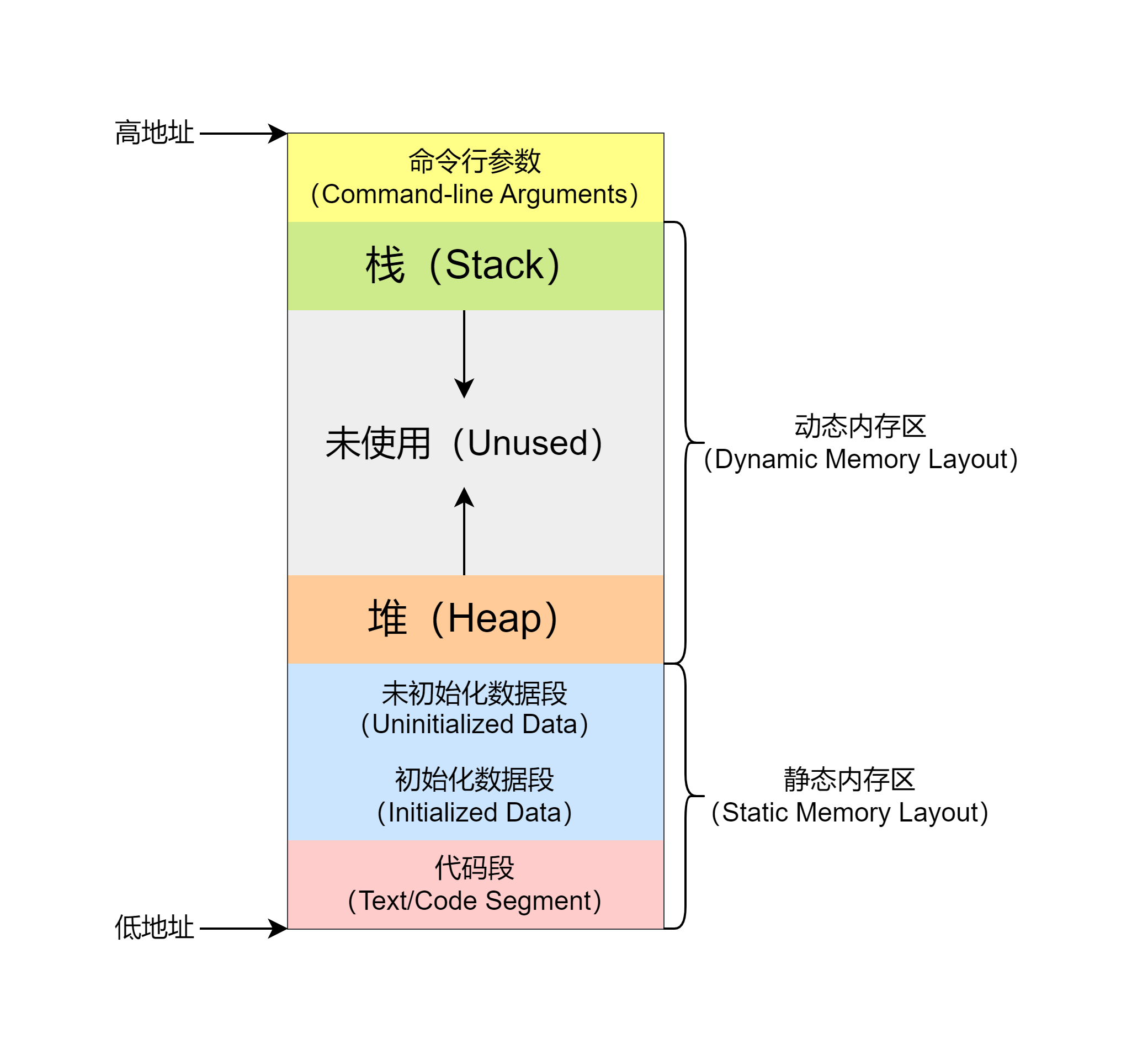
通常,一个程序的内存布局包括以下部分
代码段
初始化数据段
未初始化数据段(bss)
堆
栈
它们的位置如图所示
代码段(Text/Code Segment)
代码段就是程序代码编译后的机器码储存的位置,储存着计算机可执行的指令。
代码段通常是只读的,防止程序在运行的时候意外修改到自身的代码。
数据段
数据段只包含全局变量和静态变量,局部变量并不在这块区域里,而是在栈里。
初始化数据段(Initialized Data Segment)
顾名思义,就是被程序员手动初始化的全局变量和静态变量。
未初始化数据段(Initialized Data Segment)
由于一些历史原因,也被叫做bss段,这个名字是“block started by symbol”的简称,感兴趣的可以在wiki百科(需要魔法)上了解。
未初始化的全局变量和静态变量会被默认置0。
栈(Stack)
开头的图中可以看出,栈区和堆区在程序运行的时候朝着不同的方向增长,当两个区域碰上的时候,程序的可分配内存就耗尽了,可能造成程序异常、崩溃等。
假如向栈内写入了过多数据(如调用函数层数过多,函数使用的局部数据 ...
实现常用排序算法(三)堆排序
简介
堆排序就是利用堆进行排序,如果对堆这种数据结构不熟悉可以看一看我的这篇文章。
堆排的思想很简单,就是在需要排序的数组上建立堆,然后执行pop操作,直到堆为空,因为每次pop出来的元素都是堆中的最大/最小值,所以可以保证出来的元素有序。堆排也是一种不稳定排序,时间复杂度O(nlogn)O(n \log n)O(nlogn)。堆排序相比于先前两种排序的优势是它不需要递归,堆排序使用了更少的栈空间,防止因递归层数过多引发的低效(尤其是对于快排来说)。
实现
只要实现了堆的代码,堆排就很简单了。
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103104105106107108109110111112113114115116117class ...
主定理的应用范例
前置知识——渐进复杂度记号
本文假设你已经掌握了渐进复杂度的含义,并且熟悉大O记号表示复杂度。除了大O记号外,这里再简单介绍一下其他的复杂度记号。如果你掌握了这些符号,可以跳过本段。
渐进复杂度的记号有Θ\ThetaΘ、OOO、Ω\OmegaΩ、ooo、ω\omegaω,主定理用到了前三个,但为了完整性这里全部介绍。
Θ\ThetaΘ
若∃c1,c2,n0>0\exists c_1,c_2,n_0 \gt 0∃c1,c2,n0>0,使得∀n≥n0\forall n \geq n_0∀n≥n0有c1⋅g(n)≤f(n)≤c2⋅g(n)c_1 \cdot g(n) \leq f(n) \leq c_2 \cdot g(n)c1⋅g(n)≤f(n)≤c2⋅g(n),则称f(n)=Θ(g(n))f(n) = \Theta(g(n))f(n)=Θ(g(n))
Θ\ThetaΘ可以精确的表示算法的渐进复杂度,相应地,使用时也要注意严谨性。
用表示大小的符号类比的话,Θ\ThetaΘ就相当于===等于号。
OOO
若∃c,n0>0\exists c,n_0 \gt 0 ...

{kind=link}